Java 线程池
生活中,经常遇到“池”这个词,比如“水池”,“奖池”等。大致意思为“有好多____的地方”。
线程池,顾名思义,即“有好多线程的地方”。
A thread pool is a collection of worker threads that efficiently execute asynchronous callbacks on behalf of the application. —msdn
翻译:线程是帮应用程序执行异步(回调)功能的一组工作线程
ThreadPoolExecutor 作为 Java 最核心的线程池工具,我们看下它是如何工作的。
类图
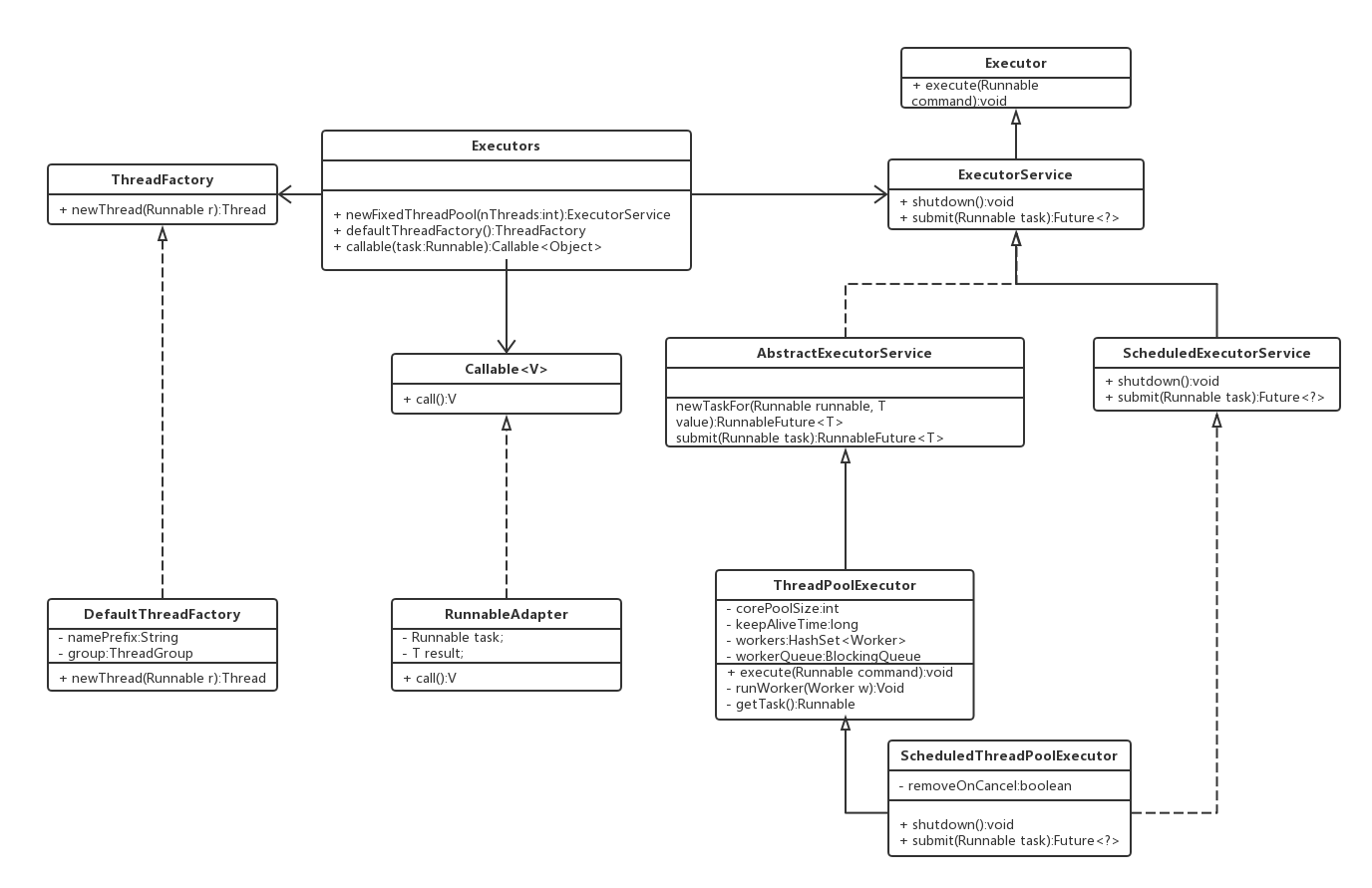
主要属性
/** 线程池的大小 */
private volatile int corePoolSize;
/** 池子里装的元素 */
private final HashSet<Worker> workers = new HashSet<Worker>();
/** 超过核心线程数的请求放到等待队列里面 */
private final BlockingQueue<Runnable> workQueue;
/** 如果请求数超过等待队列长度,执行的拒绝策略(默认是抛异常)*/
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
/** 是否允许空闲的线程执行超时释放 */
private volatile boolean allowCoreThreadTimeOut;
/** 空闲多久的线程算超时 */
private volatile long keepAliveTime;
Execute() 方法
源码–简化版
public void execute(Runnable command) {
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
// 新建一个核心 Worker,第二个参数表示是不是核心池里的 Worker
if (addWorker(command, true))
return;
}
if (workQueue.offer(command)) {
// 新建一个空的非核心池中 Worker,这里是为了支持 “核心线程数 < wc < 最大线程数” 的情况
addWorker(null, false);
}// 入队列不成功,再给一次执行机会,失败就直接使用拒绝策略了
else if (!addWorker(command, false))
reject(command);
}
流程图
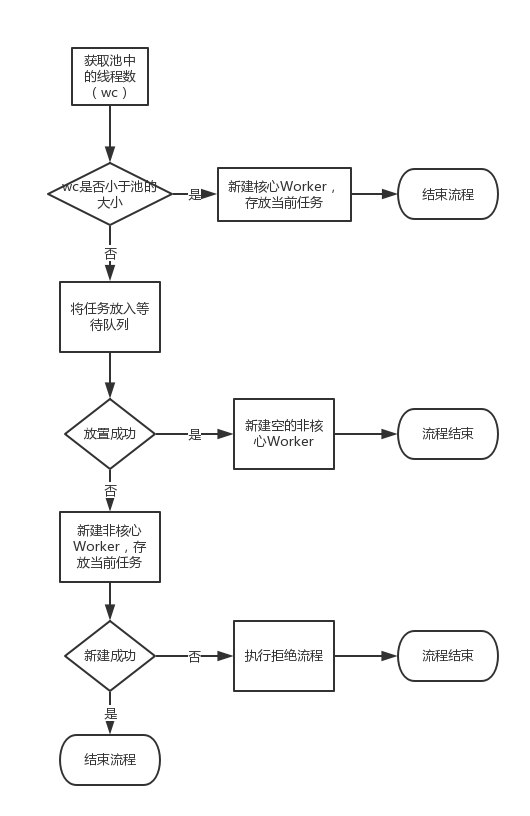
分析
通过源码可知,executor() 方法中并没有明显的执行任务的痕迹,它做的事情很简单:
- 如果池没满,就新建一个worker,把任务传过去
- 如果池满了,就将任务扔到等待队列里去
- 如果队列满,就执行拒绝策略
问题是:任务到底是什么时候执行的呢
addWorker() 方法
源码–简化版
private boolean addWorker(Runnable firstTask, boolean core) {
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
try {
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) {
workers.add(w);
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); // 重点关注
workerStarted = true;
}
}
return workerStarted;
}
// Worker 类,它也是Runnable 的一个实现
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
Worker(Runnable firstTask) {
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}
}
分析
addWorker() 的处理流程:
- 创建一个新的 Worker
- 如果当前线程池运行正常,就将新 Worker 加入到线程池
- 执行 Worker 的 start() 方法
由此我们得出,ThreadPoolExecutor 的执行原理是:
- 维护一个 Worker 集合,作为线程池
- 新任务过来后,新建一个 Worker, 把自己传给 Worker.thread, 把请求传给 Worker.firstTask
- 然后调用 Worker.start(),因为 Worker 本身是 Runnable 的实现类,所以执行了 start() 后,jvm 会创建一个线程执行 worker.run()
- 这样就达到了异步执行请求的目的
思考
按照一开始上面 execute() 的逻辑,如果任务过来时,线程池是满的,它只能直接进入到等待队列,并没有触发 Worker.run()
那等待队列里的任务是什么时候开始执行的呢?
runWorker() 方法
源码–简化版
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
try {
while (task != null || (task = getTask()) != null) {
task.run();
}
} finally {
processWorkerExit(w, completedAbruptly);
}
}
分析
从上面的代码里可以看出来:
- 在 jvm 新起线程执行 Worker.run() 的时候,首先被执行的是任务(task)的run() 方法
- 在任务的 run() 方法执行完之后,它会继续去等待队列里面取新的任务执行,直到队列为空
- 等到队列里的数据也执行完,它就执行 processWorkerExit() 方法销毁当前的 Worker
这种处理方式有几个好处:
- 如果线程空闲,就及时销毁掉,不占资源
- 等下次新批次的任务过来了,直接复用前文逻辑:新建 worker,新起线程,执行当前任务和队列中的任务
思考
runWorker() 中,它获取不到任务时,立刻就关闭了当前线程
这种方式应对任务半天不来,一来来堆的情况还是很不错的
可是为什么就不能有个等待时间呢,不然我的任务过来的时间是均匀分散的,那每批任务到了后 ThreadPoolExecutor 都要重新建立线程池?
getTask() 方法
源码–简化版
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int wc = workerCountOf(c);
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
try {
// 这段很重要
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
if (r != null)
return r;
} catch (InterruptedException retry) {
}
}
}
流程图
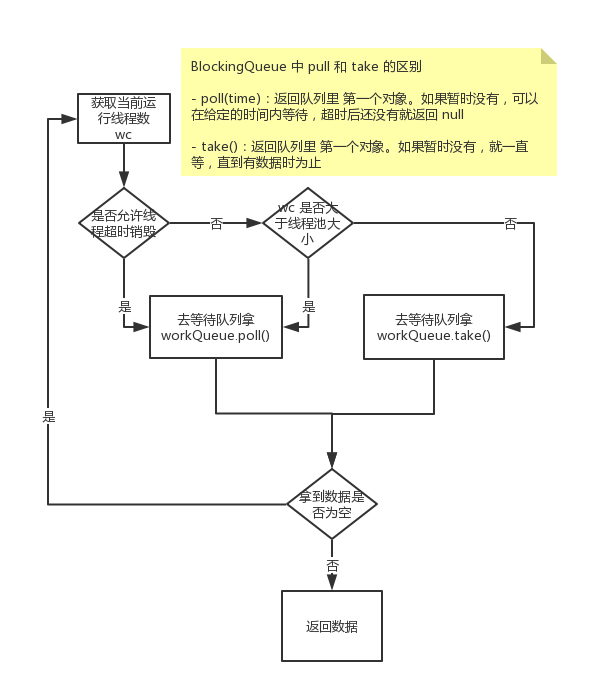
分析
它这里用了很巧妙的方式来实现线程池的等待:BlockingQueue.poll():
- 将 poll() 的超时时间跟线程的等待时间设置成一样
- 如果在该时间内拿到任务,则返回该任务给 Worker 执行
- 如果在该时间内拿不到任务,则认为超时,销毁当前Worker
另外,它还通过 BlockingQueue.take() 支持了线程永不销毁功能
结论
至此,我们总算理清了 Java 线程池工具类 ThreadPoolExecutor.execute() 的业务流程:
- 新任务 task 过来后,将它交给新建的 Worker 来执行
- 新建的 Worker 数目超过设定大小后,再来的任务就扔到等待队列中排队
- 等到队伍排满了之后,再来的任务就执行拒绝策略(如丢弃、抛异常、异步改同步、丢掉排队最久的任务)
- 当前的 Worker 执行完当前的 task 之后,会再去队列里拿等待的任务
- 在不允许超时配置下,如果拿不到就一直等在那
- 在允许超时配置下,如果拿不到,会在超时时间内等待,还拿不到,就销毁当前Worker
后记
为了阅读方便,源码示例中删除了令人眩晕的各种锁和检查机制,只保留处理流程。建议感兴趣的同学直接参考源码。
本文是对线程池的基本功能做了一个梳理,写的不严谨或者错误的地方欢迎留言指出,共同学习。
