项目背景
- 公司在淘宝有旗舰店(以下简称『淘宝店』)
- 公司有自己的官网网上商城(以下简称『官网』)
- 淘宝店跟官网数据不能实时互通,只能是 T+1 日将淘宝订单数据导入官网,供用户查询
- 淘宝店平时日订单数在一千万笔内,订单数据会在下午一点左右给到官网
- 每年『双十一』期间,日订单数在一亿左右。订单数据会在次日下午五点左右给到官网
- 为了数据能够及时导入,需要对双十一的订单数据单独优化
日常数据导入介绍
- 淘宝店的数据大体分为四个模块
- 买家数据。该数据里只有新买家的信息,老买家默认已经导入到官网系统
- 订单数据。该数据是核心交易信息,谁在何时买了什么
- 费用数据。该数据是收款和退款信息,收到哪个用户多少钱,退了哪个用户多少钱
- 退货数据。该数据是退货的详细信息,哪个用户申请了退货,退货进度到哪儿了
- 四个模块中,买家数据跟退货数据比较少,订单和费用的数据比较多
- 日常导入 TPS = 700
- 处理流程图
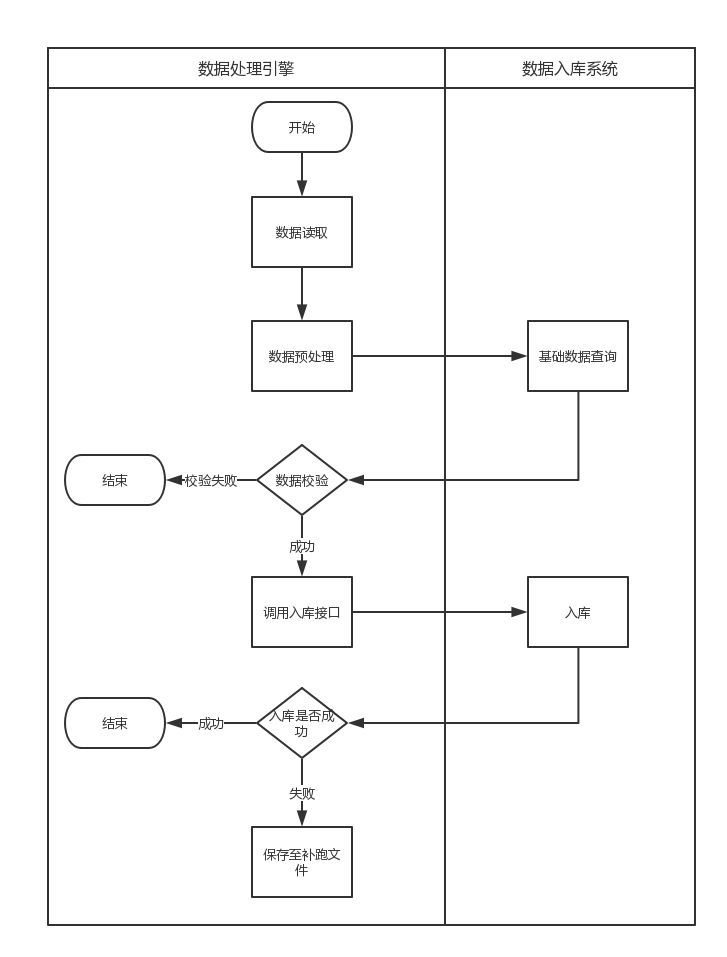
优化过程
加机器
优化问题,首先想到的就是加机器。『加人』对于项目来说虽然不是银弹,『加机器』理论上来说却是的。
但是不能一开始就寄希望于加机器,原因有两点:
- 数据库连接数是一定的,应用机器数量就有了上限
- 加机器有效之后,开发人员会失去优化代码动力。如果上线当天出现别的问题,没有快速有效的解决方案
查找性能优化点
使用 AOP 设置切面,统计调优相关所有方法的执行频率和执行时间
优化业务流程
- 找到执行频率高或者执行时间长的代码
- 看能否业务流程上优化
- 因为历史原因,淘宝店数据跟官网数据走的同一个流程,所以为了适配两者逻辑,代码都纠缠到一起。要拆开
- 相同判断在多个 service 做了,service 互相调用就会重复校验
- 不同产品校验逻辑不同,拆开分别校验
- 梳理业务流程,该删删该减减
- 逻辑下放,将部分校验逻辑从数据处理引擎迁移到入库系统中,减小入库系统负载
本地缓存
应用机器内存使用率不高,有些高频数据小量数据可以使用本地缓存
- 增值税缓存
计算增值税 BigDecimal,效率不高。考虑到淘宝店产品不多,没有必要每次都计算一次增值税。把每个产品的增值税缓存
- 产品信息缓存
订单、费用、退货模块都会去查询产品相关信息,产品信息可以缓存
异步线程池
应用机器 CPU 使用率也不高,可以考虑使用异步线程池接收数据引擎过来的请求
- 数据引擎跟入库系统使用的是 HSF 同步调用的方式,以便获取数据入库的实时处理结果
- 每台机器的 HSF 连接数是固定的,如果数据处理速度不高,会导致 HSF 连接打满,进而数据引擎被阻塞,无法发挥最大作用
考虑到双十一期间数据处理都是受到监控,因此在数据过来时,使用线程池异步处理,既可以规避 HSF 连接不够的问题,又能提高机器的 CPU 使用率
线程池方案:
- 核心线程:150
- 最大线程:150
- 队列长度:3W
- 拒绝策略:同步(CallerRunsPolicy)
完善监控
- 采集每台机器的内存、CPU信息
- 采集每台机器的线程数和队列阻塞情况
- 根据机器的状况实时调整线程数
分布式缓存
- 有些订单之间会有关联,子订单入库时会去查找父订单,为减小查询次数,父订单入库时异步存入缓存
- 费用数据入库前会查询订单数据,为减小查询次数,将订单数据异步存入缓存
热点数据
淘宝店数据进来时,按模块划分为 4 个数据文件,但是同一个文件中数据是无序的。
数据刚开始入库时,因为缓存中并没有数据,所以处理很慢,容易将线程队列打满,继而将 HSF 连接池打满。
可以在书库入库前,做一次清理,将热点数据(比如父订单)先以一个较小的并发执行,等待跑完后再用较大的并发集中跑剩下数据
